Benefits of Workflows and Standards §
Why Use Workflows? §
Workflows and using workflow tools help make your computation methods portable, maintainable, reproducible and shareable. Often analysis methods contain many steps, perhaps in multiple languages and workflows help researchers document, run and maintain these complicated analyses.
Using a workflow system rather than a series of scripts has a number of benefits including abstraction, scaling, automation, and provenance (ASAP).
Workflows enable a clear abstraction about the components of your analysis, the relationship between the components and the inputs and outputs for each component allows for a well-labeled analysis with documented expectation. This abstraction helps enable the other benefits of scaling, automation and provenance.
Workflow execution can be parallelized or distributed making use of cluster, cloud, and high performance computing (HPC) environments. This helps to solve larger problems and analyze larger datasets faster.
Automation helps when running repetitive pipelines, for example when running
parameter sweeps or the same analysis on different sets of data. Workflow engines
can use the inherent abstraction of workflows to efficiently track, plan and
manage the execution of workflow components.
Lastly, provenance tracking helps with auditing, tranparency, and validation.
Ultimately, using workflows in the long run helps save time and effort and
allows for easier scaling, tracking, sharing and reuse.
Why Use a Standard? §
A standard for sharing and reusing workflows can provide a solution to describing
portable,re-usable workflows while also being workflow-engine and vendor-neutral.
Although workflows are very popular
(see our list of existing workflow systems),
prior to the CWL standards every workflow system was incompatible with every other.
This means, those users not using the CWL standards are required to express their
computational workflows in a different way every time they have to use another
workflow system. This greatly hampers reuse and collaboration.
When to Use CWL? §
The CWL standards were designed for a particular style of
command-line tool based data analysis.
CWL is for dataflow style batch analysis consisting of command line programs. It is not designed for supporting safe interaction with stateful (web) services, real-time communication between workflow steps, or workflows that need particular steps run at or during a
specific day/time-frame.
Reusability and Reproducibility with CWL §
CWL workflows are portable, reusable, and flexible. Reproduction, reuse, and replication of computational methods requires a complete description of what computer applications were used, how exactly they were used, and how they were connected to each other. To this end, CWL enables portability by being explicit about inputs/outputs to form the data flow, data locations and execution models. CWL supports using software container technologies, such as Docker and Singularity, to enable portability. For increased flexiblity, individual CWL tool definitions can be reused in any new workflow.
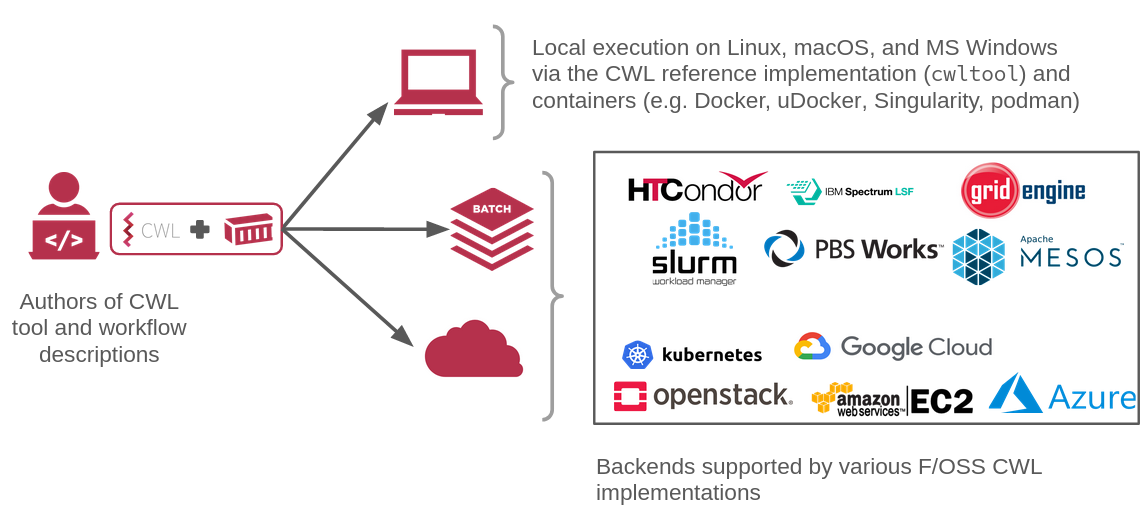 Example of CWL portability. The same CWL workflow description can run on a laptop,
on any batch production-environment, and on any common public or private cloud.
Example of CWL portability. The same CWL workflow description can run on a laptop,
on any batch production-environment, and on any common public or private cloud.
Benefits of CWL including flexibility, portability, and scalability. CWL is well suited for describing large-scale workflows in cluster, cloud and high performance computing environments where tasks are scheduled in parallel across many nodes.
Parallelization and Scale with CWL §
CWL workflows describe each step with explicit inputs and outputs. Workflow steps
in CWL are not necessarily run in the order they are listed, instead the order
is determined by the dependencies between steps. Workflow steps which do not
depend on one another may run in parallel.
Additionally, the scatter feature in CWL allows the repeated execution of a CWL step in parallel (depending on the resources available) over a list of inputs. This can be done without requiring the modification of the underlying tool description.
By design, the CWL standards do not impose any technical limitations to the size of files processed or to the number of tasks run in parallel. The major scalability bottlenecks are hardware-related — not having enough machines with enough memory, compute or disk space to process more and more data at a larger scale. As these boundaries move in the future with technological advances, the CWL standards should be able to keep up and not be a cause of limitations.
Different implementations of the CWL standards can provide different capabilities in terms of scaling and access to HPC resources.
Different implementations of the CWL standards can provide different levels of scability.